What I Think the Voynich Manuscript Is (and Isn't)
There's a book at Yale that nobody can read.
The Voynich Manuscript is a 240-page illustrated codex written in an unknown script, filled with drawings of plants that don't correspond to any known species, naked women swimming through networks of green tubes for reasons that are not explained, and astronomical diagrams that appear to depict a cosmos that does not exist.1 The vellum has been radiocarbon dated to 1404-1438. People have been trying to crack it for over a century. Codebreakers from both World Wars took shots at it. The NSA took a shot at it. Academics, amateurs, at least one person who claimed the answer came to them in a dream. Nobody has succeeded. The full manuscript is digitized and freely available if you'd like to try.
I spent a few months throwing computation at it, and I just put out a paper on what I found. This post is the non-academic version. No Greek letters, no statistical notation, just the ideas.
The question that makes this hard
The fundamental debate in Voynich research is not "what does it say." It's more basic than that, and considerably more uncomfortable: does it say anything at all?
There are smart, serious people on both sides. The hoax camp (which has gotten considerably more rigorous since the 2022 Malta Conference, the field's first dedicated peer-reviewed meeting) points out that you can produce text with Voynich-like statistical properties using relatively simple methods. A grid with sliding windows. A self-citation algorithm. Or, most devastatingly, just asking regular people to make up nonsense text that "feels" like language, which turns out to produce output that is statistically indistinguishable from real language by most standard measures.2
The meaningful-text camp points to Zipf's law compliance, entropy profiles, keyword clustering across sections, and the kind of internal structure that seems like it would be very hard to fake in 1420 without access to information theory, which would not be invented for another 530 years.
The uncomfortable truth, which the field has slowly come to accept (largely because of the Malta conference), is that statistical tests alone cannot resolve this. Meaningless text and meaningful text look surprisingly similar when you just measure their statistics. Which means that anyone (including me) claiming to have found "linguistic structure" in the Voynich needs to demonstrate that whatever they found couldn't be produced by a moderately clever person with a table and a lot of vellum.
What I actually did
I ran two completely independent analysis pipelines on the manuscript's transcription (about 36,000 words in the standardized EVA transliteration). One treats each character as a letter. The other treats each character as a syllable. They don't share code, assumptions, or methodology. They were developed months apart and I deliberately did not look at the results of one while building the other, because confirmation bias in Voynich research is very easy.3
The reason for running two is simple: if they agree on something, that agreement is less likely to be an artifact of one method's assumptions. They agreed on quite a lot.
Both pipelines converge on the same source language: Romance, specifically a mix of Latin and Italian. Both confirm that the text splits into two distinct subsystems (something a Navy cryptographer named Prescott Currier noticed back in 1976, and which has held up under every subsequent analysis). Both find genuine morphological structure, words built from meaningful prefixes, roots, and suffixes. And both point to medieval medical and herbal content, which is consistent with the manuscript's illustrations (the plants, the pharmaceutical containers, the recipe-like text blocks).
The hypothesis: medieval Italian shorthand
Here's the part that's new, and also the part where the probability that I'm wrong is highest, because novel hypotheses about the Voynich have a historical success rate of approximately zero. But to understand the hypothesis, it helps to see the timeline it sits inside.
Historical timeline
Roman shorthand. ~13,000 whole-word signs attributed to Cicero’s secretary Tiro.
Irish, Lombard, and Frankish scribal traditions merge in the Apennines south of Pavia.
Genoese notaries reorganize Tironian signs into CV syllables. Costamagna (1953) documents 228 entries.
Syllabic shorthand falls out of use. Survives only in archival manuscripts.
The only known 15th-c. northern Italian cipher texts. Sign families from base-form modification.
Five scribal hands, shared encoding, pharmaceutical Latin-Italian. 56 signal words validated (p = 0.001).
German annotators (Bavarian, Swabian). Reaches Prague by the 17th century.
I'm proposing that the Voynich is written in Italian syllabic tachygraphy, a medieval shorthand system documented in notarial archives from Genoa, Lombardy, and Liguria by an archivist named Giorgio Costamagna in 1953.4 This is not the kind of shorthand you're imagining. Instead of one symbol per word (like Gregg or Pitman), each symbol represented a consonant-vowel syllable. Ba, di, se, that kind of thing. A single base shape could encode multiple syllable values by changing the entry angle, the thickness of the stroke, or by adding a small tick or serif. It was used by notaries in northern Italy and died out around the 11th or 12th century.
Here's what Costamagna's catalog actually looks like. This is Tavola 1 of 13, showing syllables ac through bis out of 228 total entries. Each row is a set of glyph variants for related syllable values:
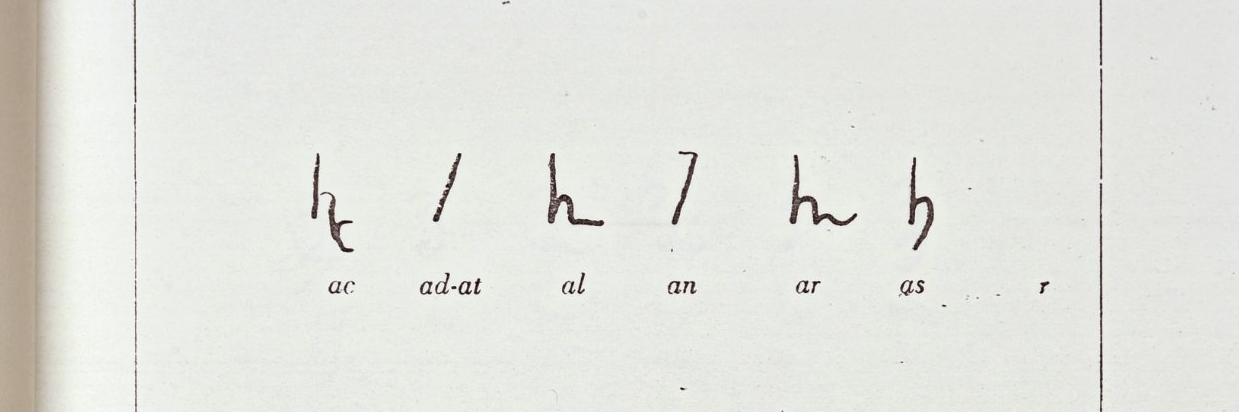
Which means it was already 300 to 400 years archaic by the time the Voynich was made. But someone with access to older archives could have recovered it. And here's where it gets interesting: when I built a simulated tachygraphic encoding and compared its statistical fingerprint against the Voynich's, the match was better than 13 other encoding schemes I tested, including the most recent serious alternative (a verbose substitution cipher called the Naibbe cipher, published last year, which I was genuinely worried would sink the whole project but which turned out to be decisively rejected by the entropy analysis). The Naibbe shifts entropy in the exact opposite direction from the Voynich. Mirror-image signatures. Not close.
The tachygraphic model also makes a prediction that no other tested model gets right. Currier noticed in 1976 that word endings in the Voynich predict the beginning of the next word, roughly four times more than you'd expect by chance. If the Voynich's "words" are actually syllables of longer underlying words (which the tachygraphic model predicts), this anomaly is explained: adjacent syllables of the same word share phonotactic constraints. The simulation matches the observed effect. Every other model I tested, including the stochastic model that actually scores higher on the entropy measure, produces essentially zero cross-boundary prediction. Tachygraphy is the only tested model that passes both tests.
What I decoded (and what I didn't)
The assignment table I built (25 stroke-triples mapping to consonant-vowel syllables, if you want the technical version) produces 56 statistically validated "signal words." These are words that show up in real Voynich text significantly more often than in synthetic text with matched statistics. To test whether the table was producing real results or just getting lucky, I ran 1,000 random assignment tables through the same pipeline. Only 1 out of 1,000 produced as many signal words as mine.5
More interesting than the count is what the words are. My table produces five conjugated forms of the Italian verb dire ("to say"): dise, dice, dico, dicu, diga. A complete set of Romance function words (articles, prepositions, pronouns, conjunctions). And pharmaceutical terminology: senna, coralli (corals, a standard medieval ingredient), ratione (by method), stercora (dung, which yes, was used medicinally, and which I bring up partly because it's a real finding and partly because I enjoy the sentence "I found statistically significant evidence of dung"). Only 1.1% of random tables produce all three of these things simultaneously.
There are also 22 word-level identifications where a partially decoded pattern uniquely matches a pharmaceutical Latin word that recurs across multiple pages: diasene (a senna compound), radicom (root, in the accusative case), commune (common). When I ran the same method on 1,000 random tables, 74.4% of them produced zero. Mine produced 22.
The paper also identifies a system of coda consonants (closing sounds that turn two-character syllables into three-character ones, like di becoming din or dis). Three specific stroke types in the manuscript encode n, s, and t, and they map to Latin grammatical endings with remarkable consistency: the -s stroke marks second person singular 99% of the time, the -t stroke marks third person singular 95% of the time. When I randomly shuffled which stroke type gets which consonant, zero out of 500 shuffles produced a grammatical distribution as close to pharmaceutical Latin as the real mapping. That's the project's strongest individual null test.
So: individual words, syllables, and grammatical endings, yes. But connected readable text, passages that a Latinist would look at and say "that's a sentence," no. Not yet. The paper's title comes from this gap: the voice but not the song. You can hear something. You can't make out the lyrics.
The thing I'm most proud of (it's a methodology finding)
The single most useful thing in this paper might not be about the Voynich at all, which is either a testament to the generalizability of good methodology or a damning commentary on the state of my actual decipherment progress. Possibly both.
When you run a decipherment and check your decoded text against a dictionary, you get a hit rate. My initial hit rate was 43.6%. That sounds great. Really encouraging. Except that when I ran the same pipeline on null corpora (synthetic text with the Voynich's character statistics but no linguistic content), the null text hit the dictionary at 37.6%. So far so good, a 6-point gap. Something is there.
But when I looked at which specific tokens were hitting, the picture collapsed. The oversized dictionary (131,000 entries) wasn't just generating genuine matches. It was generating massive "anti-signal": tokens where the null corpora matched the dictionary but the real Voynich didn't. This anti-signal nearly canceled the genuine signal. Net signal with the full dictionary: 1.0%. One percent. Of the apparent 43.6%, essentially all of it was noise.6
Switching to a right-sized 10,000-word dictionary fixed the problem. Anti-signal dropped from 15.5% to 3.6%. Net signal rose to 15.0%. The genuine decoded vocabulary expanded from 9 to 51 words. Lower than the inflated number, but now real.
This matters beyond the Voynich. Anyone doing computational decipherment and reporting dictionary match rates is probably inflating their results by an order of magnitude if they're not controlling for this. Which, as far as I can tell, most people aren't.
What the paper doesn't claim
I want to be explicit about this because Voynich research has a history of overclaiming that borders on the pathological. Roughly once a year, someone announces they've cracked the manuscript, the media reports it uncritically, and within a week the Voynich research community has identified the fatal flaw. I would like to not be that person.
This is not a decipherment. I can't read the manuscript. Individual words and syllables have been decoded, but the gap between decoded words and readable text is enormous, roughly comparable to the gap between knowing what individual road signs mean and being able to navigate a city. The paper calls itself "hypothesis development," and I mean that literally. I'm proposing a mechanism, showing it fits the data better than alternatives, and demonstrating that the decoded output has statistically significant linguistic structure. That is a long way from reading the thing.
The hoax hypothesis is not ruled out. My strongest finding (the tachygraphic encoding match) is consistent with the text being meaningful, but I cannot prove it wasn't an elaborate construction that happens to mimic an encoding system.
And the dialect identification is messy. The decoded vocabulary shows Tuscan grammar but northern Italian sound changes. It looks like a literate northern Italian scribe writing in a Latin-influenced standard while their native dialect leaks through. That's consistent with the time period and geography, but it could also be an artifact of the decoding method producing Italian-ish output from a fundamentally non-Italian source.
Where it goes from here
The tachygraphic hypothesis makes a testable prediction: the assignment table should match the historical shorthand catalog Costamagna documented in 1953. My statistically derived table matches his catalog on every structural dimension I tested (grid dimensions, syllable types, modifier functions, coda consonant system, even the number of ambiguous signs: exactly 3 in both). That's encouraging.
There's a variant of this that I find increasingly hard to dismiss: the manuscript we have might not be the original. The radiocarbon dating tells us when the calf died, not when the content was composed. The vellum is early 15th century. The shorthand system is 11th century at the latest. One explanation is that someone in 1420 dug up an archaic encoding from old archives and used it to write a new book. The other explanation is that someone in 1420 dug up an old book and copied it onto new vellum before it fell apart.
The physical evidence is at least consistent with copying. The scribes made almost no corrections, which is unusual for original composition but normal for careful transcription from an exemplar. Five different hands share the same encoding, which makes more sense as a coordinated copying project than as five people independently composing in a dead shorthand. And the dialect mess (Tuscan grammar, northern sound changes) could partly reflect scribes unconsciously modernizing the language as they copied, the way every medieval copyist did with every text they touched.
If the content is older than the vellum, it would close the gap that makes the tachygraphic hypothesis feel like a stretch. You don't need to explain how a 15th-century scribe recovered a 300-year-dead shorthand system and composed in it. You just need to explain how they copied something they could see but might not have fully understood. That's a much smaller ask. Monks copied Greek manuscripts they couldn't read for centuries.
I don't have evidence for this beyond the circumstantial, and I want to be clear that the paper doesn't argue for it. But if someone with paleographic expertise wanted to look at the manuscript's line spacing, ruling patterns, and quire construction for signs of copying rather than composition, I'd be very interested in what they found.
But the real test is whether someone can extend this to produce readable text. The honest answer is: I don't know if that's possible with computational methods alone. The assignments might be conventional (learned from a tradition rather than derivable from first principles), the same way Linear B couldn't be cracked by statistics alone until Michael Ventris made the right guess about the language. And Ventris had the advantage of working with a script that turned out to encode a known language (Greek). If the Voynich encodes a 15th-century northern Italian medical vernacular written in a shorthand system that died out three centuries before the manuscript was created, the Rosetta Stone equivalent might not exist.
The paper is on this site, linked below. If someone can push this further, I'd like that.
The paper is "The Voice But Not the Song: A Shorthand Hypothesis and the Statistical Fingerprint of the Voynich Manuscript". Full text and PDF available there. Code: Approach 1 and Approach 2. The full digitized manuscript is available from Yale's Beinecke Library.
Footnotes
-
The naked-women-in-tubes section, which scholars call the "balneological" section (from the Latin for "bathing"), is one of those things that, once you see it, you cannot un-see, and also led to alien theories? ↩
-
This is the Gaskell and Bowern (2022) result, and it is, in my opinion, the single most important finding in Voynich studies in the last decade. It doesn't prove the manuscript is a hoax. What it does is demolish the argument that "the text is too statistically complex to be meaningless." It turns out humans are just really good at generating complex-looking meaningless text. ↩
-
The history of Voynich research is essentially a catalog of smart people who found exactly what they expected to find. If you go in believing the text is Latin, you will find Latin. If you believe it's Hebrew, you'll find Hebrew. If you believe it's proto-Romance, you'll find proto-Romance. The manuscript is a linguistic Rorschach test, and the only defense against it is aggressive null-model testing, which is why roughly a third of this paper is about the null models. ↩
-
Costamagna's 1953 monograph is held by essentially no library outside Italy, which I discovered after several weeks of increasingly desperate interlibrary loan requests. The Biblioteca Nazionale Centrale di Firenze tracked it down for me. The Biblioteca Marucelliana, also in Florence, provided a complete photographic reproduction. I want to be clear about what happened here: a guy in Seattle with no institutional affiliation emailed two Italian research libraries and said, basically, "I'm trying to decode a medieval manuscript and I need a book from 1953 that nobody has," and they just... helped. Extensively. If you have ever doubted whether librarians are the best people on earth, I invite you to reconsider. ↩
-
To be precise: the real table produces 56 signal words. Random tables average 33. The p-value is 0.001, which means there's a 1 in 1,000 chance of getting this result by accident. In Voynich research, I will take 1 in 1,000. ↩
-
I realize there's something slightly awkward about publishing a paper whose methodology section is essentially titled "here's how I discovered my own results were mostly fake." But I would rather have a small real number than a large fake one. ↩